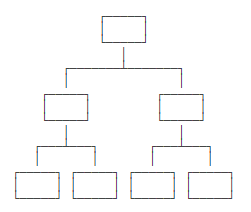
作为数据相关的产物小白,在平常进修工作中经常能看到大概听到大师在会商数据库,数据仓库,数据集市,数据湖还有比来比力火的数据中台,似乎这些名词都与数据存在着联系,检察各类相关书籍,大部分书籍中的内容过于专业艰涩难明。 那末这篇文章连系我堆集的相关方面常识,向大师先容一下上述这些名词的区分与联系,以及在各类企业及营业上的适用范围,若有不正确的地方,希望大师停止斧正。 一、作甚数据库相信大部分有些许技术布景的同学们都对数据库有一定的领会,数据库是“依照数据结构来构造、存储和治理数据的仓库”,一般分为“关系型数据库”与“非关系型数据库”。 1. 关系型数据库现实上曩昔的数据库一共有三种模子,即条理模子,网状模子,关系模子。 (1)首先条理模子的数据结构为树状结构,即是一种高低级的层级关系构造数据的一种方式:
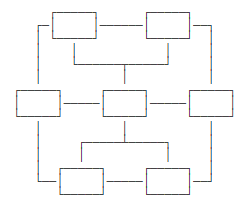
(2)网状模子的数据结构为网状结构,行将每个数据节点与其他很多节点都毗连起来:
(3)关系模子的数据结构可以看做是一个二维表格,任何数据都可以经过行号与列号来唯一肯定:
由于相比于条理模子和网状模子,关系模子了解和利用最简单,终极基于关系型数据库在各行各业利用了起来。 关系模子的数学道理触及到关系,元组,属性,笛卡尔积,域等等使人头秃的数学术语,这里大师假如感爱好可以看看相关的文献,我就不放出来催眠大师了,虽然数学道理很是复杂,但假如用平常进修工作的具体事务举例,就相对轻易了解。 我们以某公司的员工信息表为例,该公司的员工信息可以用一个表格存起来。而且界说以下:
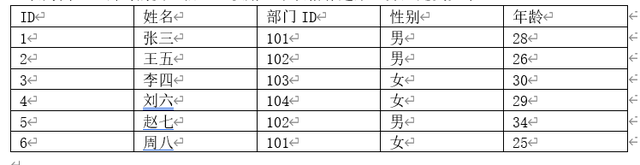
同时部分ID对应这另一个部分表:
我们可以经过给定一个部分称号,查到一条部分的记录,按照部分ID,又可以查到该部分下的员工记录,这样二维的表格就经过ID映照建立了“一对多”的关系。 常用的关系型数据库有Oracle,Microsoft SQL Sever,MySQL,DB2。数据库的说话根基上围绕着“增删改查”来停止的,语法相对简单,大师有爱好可以下载MySQL自学,网上有很多免费的材料。 2. 非关系型数据库非关系型数据库是以工具为单元的数据结构,非关系型数据库凡是指数据以工具的形式存储在数据库中,而工具之间的关系经过每个工具本身的属性来决议。 简单来说非关系型数据库与传统的关系型数据库的区分在于非关系型数据库首要存储没有牢固格式的超大范围数据,例如键值对型,文档型,列存储类数据,常见的非关系型数据库有Hbase,Redis,MongoDB,Neo4j等。现在我们凡是所说的数据库指的是关系型数据库,非关系型数据库大师领会即可。 二、数据库→数据仓库1. 例子随着企业的成长,线上的营业系统随着营业停止会源源不竭的发生数据,一般这些数据会存储在我们企业的营业数据库中,也就是上面讲到的关系型数据库,固然分歧的企业利用的数据库能够不尽不异例如上述的Oracle,Microsoft SQL Sever,MySQL等,可是底层的技术逻辑都大同小异,这些营业数据库支持着我们营业系统的一般运转。 可是当我们线上的营业系统运转跨越一按时候后,内部积存的数据会越来越多,对我们的营业数据库会发生一定的负载,致使我们营业系统的运转速度较慢,这些数据中有很大一部分是冷数据,由于营业系同一般对我们近期的一些数据比如当天或一周内这些数据挪用比力频仍,对照力早的数据挪用的频次就会很低。 同时呢今朝由于数据驱动营业概念的兴起,各营业部分需要将营业系统的营业数据提取出来停止分析以便更好地停止帮助决议,但各部分需求的数据品种千差万别,接口扑朔迷离,过量的数据查询剧本以及接口的接入致使营业数据库的稳定性下降。 为了避免冷数据与历史数据收集对我们营业数据库发生的影响,故障我们营业的一般运转,企业需要定期将我们冷数据从营业数据库直达移出来存储到一个专门寄存历史数据的仓库里面,各部分可以按照本身营业需要停止数据抽取,这个仓库就是数据仓库。 2. 数据仓库的特征连系上述例子,我们得出数据仓库的以下特征:
3. 数据库VS数据仓库再深入一些,我们此时要引入两个新的名词OLTP(On-Line Transaction Processing)联机事务处置与OLAP(On-Line Analytical Processing)联机分析处置,乍听两个名词感受很高峻上,我们此时要关注两个单词的区分,“Transaction”为事务,营业。 所以营业数据库也就是我们之前讲的关系型数据库属于OLTP范例,该范例偏重于根基的,平常的事务处置,是营业系统的“压舱石”,保持一般运转,而“Analytical”则为分析,数据仓库就属于OLAP范例,该范例偏重于复杂的分析,查询操纵,是营业系统的“船帆”,供给决议支持。 三、数据仓库相信经过上述的案例,我们对数据仓库有了大致的熟悉,一个简单的数据仓库结构以下图所示,那末接下来我们讲讲数据仓库的相关常识点:
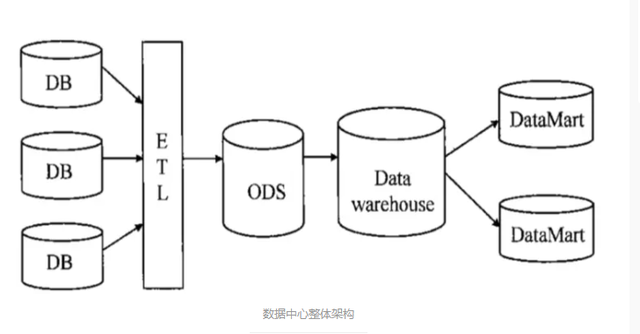
1. ETL(extraction-transformation-load)抽取-转换-加载 (1)extraction(抽取) 不是一切出现在营业数据库中的数据都需要抽取,抽取需要在调研阶段做大量的工作,首先要搞清楚数据是从几个营业系统中来,各个营业系统的数据库办事器运转什么,能否存在手工数据且手工数据量有多大,能否存在非结构化的数据,某些数据对于分析没有任何代价,这类数据能否需要剔除,当收集完这些信息以后才可以停止数据抽取的设想。 (2)Transformer(转换) 也就是数据的清洗,数据仓库分为两部分,ODS(操纵数据存储)及DS(数据仓库),凡是的做法是从营业系统到ODS做清洗,将脏数据与不完整数据过滤掉,在从ODS到OW的进程直达换,停止一些营业法则的计较,聚合及数据转换。 a. 数据清洗:营业系统→ODS的进程,过滤那些不合适要求的数据,将过滤的成果交给营业主管部分,确认能否过滤掉还是由营业单元批改以后再停止抽取。 b. 数据转换:ODS→DS的进程,首要停止分歧维度的数据转换、数据颗粒度的转换,以及一些营业法则的计较。
(3)Load(加载) 将清洗及转换过的数据加载到数据仓库,一般分为全量加载及增量加载。
小结:ETL是数据仓库开辟中最耗资本的一环,是以该环节要整理各营业系统中混乱无章的数据,工作量很大,但也是搭建数据仓库的最重要的环节。 2. ODS 操纵数据存储ODS(Operation Data Store)操纵数据存储在营业数据库与数据仓库之间构成一个隔离,其存在可以避免数据仓库间接挪用营业数据库的数据,连结数据在结构上与营业数据库分歧,起到进步营业数据库稳定性,下降数据抽取复杂性的感化。 鉴于ODS上述特点,数据会依照特按时候源源不竭地写入ODS中,且一经写入的数据不能被删除,点窜。所以为了进步ODS的运转效力,一般ODS会斟酌利用散布式文件存储系统。 3. DM数据集市DM(Data Market)数据集市是以某个营业利用为动身点而扶植的部分的数据仓库,所以DM数据集市的特点在于结构清楚,针对性强且扩大性杰出,由于仅仅对某一个范畴建立,轻易保护点窜。 数据集市分为自力数据集市与非自力数据集市,其中自力数据集市有独占的源数据库与ETL架构。而非自力数据集市则没有自己的源数据,全数数据位于数据仓库,开辟职员经过权限的设备,为用户供给面向其营业的数据,该数据为数据仓库的子集。 四、数据仓库VS数据湖对于治理企业的职员一般来说有两种特征,开放性与有序性,创业公司的人思惟常常比力开放,但治理大型公司的人更重视次序,同理这个概念可以利用在现在的数据结构中,开放意味着轻易接管新信息以及采取新的概念,创业公司拥抱开放的缘由他们必须学会打破常规,在市场中缔造新的代价。 有序则指的是采纳已证实是成功的形式,这凡是意味着解除那些不太能够成功的想法和信息。 1. 开放性→数据湖开放性的特征间接指向数据湖的概念,数据湖是新数据可以不受任何限制地进入的地方,在这里,任何数据都可以存在,是以这里是发现新想法,用数据尝试绝妙来历,但同时由于其对任何数据的开放性,使得其缺少成心义的结构,对于数据量较大时,就显得有些紊乱了。 2. 有序性→数据仓库有序性间接指向数据仓库,在数据仓库中,我们将维度和目标视为可查询的,这是可以同一治理,且更轻易被不竭扩大的受众消耗。 五、后续由于篇幅所限,本篇文章为《10分钟带你领会数据库、数据仓库、数据湖、数据中台的区分与联系》的第一部分,第二部分会为大师先容湖仓一体,数据中台的相关常识以及数据库、数据仓库、数据湖与数据中台在各类企业及营业上的适用范围。 本文由 @愉快的赐与 原创公布于大家都是产物司理,未经答应,制止转载 题图来自 Unsplash,基于 CC0 协议 |